![]()
Getting Started with Semantic Segmentation using IceVision
Install
Install from pypi...
# Torch - Torchvision - IceVision - IceData - MMDetection - YOLOv5 - EfficientDet Installation
!wget https://raw.githubusercontent.com/airctic/icevision/master/icevision_install.sh
# Choose your installation target: cuda11 or cuda10 or cpu
!bash icevision_install.sh cuda11
... or from icevision master
# # Torch - Torchvision - IceVision - IceData - MMDetection - YOLOv5 - EfficientDet Installation
# !wget https://raw.githubusercontent.com/airctic/icevision/master/icevision_install.sh
# # Choose your installation target: cuda11 or cuda10 or cpu
# !bash icevision_install.sh cuda11 master
Imports
from icevision.all import *
[1m[1mINFO [0m[1m[0m - [1mThe mmdet config folder already exists. No need to downloaded it. Path : /home/ubuntu/.icevision/mmdetection_configs/mmdetection_configs-2.16.0/configs[0m | [36micevision.models.mmdet.download_configs[0m:[36mdownload_mmdet_configs[0m:[36m17[0m
Getting and parsing the data
data_url = 'https://s3.amazonaws.com/fast-ai-sample/camvid_tiny.tgz'
data_dir = icedata.load_data(data_url, 'camvid_tiny') / 'camvid_tiny'
codes = np.loadtxt(data_dir/'codes.txt', dtype=str)
class_map = ClassMap(list(codes))
images_dir = data_dir/'images'
labels_dir = data_dir/'labels'
image_files = get_image_files(images_dir)
records = RecordCollection(SemanticSegmentationRecord)
for image_file in pbar(image_files):
record = records.get_by_record_id(image_file.stem)
if record.is_new:
record.set_filepath(image_file)
record.set_img_size(get_img_size(image_file))
record.segmentation.set_class_map(class_map)
mask_file = SemanticMaskFile(labels_dir / f'{image_file.stem}_P.png')
record.segmentation.set_mask(mask_file)
records = records.autofix()
train_records, valid_records = records.make_splits(RandomSplitter([0.8, 0.2]))
sample_records = random.choices(records, k=3)
show_records(sample_records, ncols=3)
0%| | 0/100 [00:00<?, ?it/s]
0%| | 0/100 [00:00<?, ?it/s]

Transforms and datasets
presize, size = 512, 384
presize, size = ImgSize(presize, int(presize*.75)), ImgSize(size, int(size*.75))
aug_tfms = tfms.A.aug_tfms(presize=presize, size=size, pad=None,
crop_fn=partial(tfms.A.RandomCrop, p=0.5),
shift_scale_rotate=tfms.A.ShiftScaleRotate(rotate_limit=2),
)
train_tfms = tfms.A.Adapter([*aug_tfms, tfms.A.Normalize()])
valid_tfms = tfms.A.Adapter([tfms.A.resize(size), tfms.A.Normalize()])
train_ds = Dataset(train_records, train_tfms)
valid_ds = Dataset(valid_records, valid_tfms)
ds_samples = [train_ds[0] for _ in range(3)]
show_samples(ds_samples, ncols=3)

UNET model and dataloaders
model_type = models.fastai.unet
train_dl = model_type.train_dl(train_ds, batch_size=8, num_workers=4, shuffle=True)
valid_dl = model_type.valid_dl(valid_ds, batch_size=8, num_workers=4, shuffle=False)
backbone = model_type.backbones.resnet34()
model = model_type.model(backbone=backbone, num_classes=class_map.num_classes, img_size=size)
Defining and training the fastai learner
def accuracy_camvid(pred, target):
# ignores void pixels
keep_idxs = target != class_map.get_by_name('Void')
target = target[keep_idxs]
pred = pred.argmax(dim=1)[keep_idxs]
return (pred==target).float().mean()
learn = model_type.fastai.learner(dls=[train_dl, valid_dl], model=model, metrics=[accuracy_camvid])
learn.lr_find()
SuggestedLRs(valley=9.120108734350652e-05)
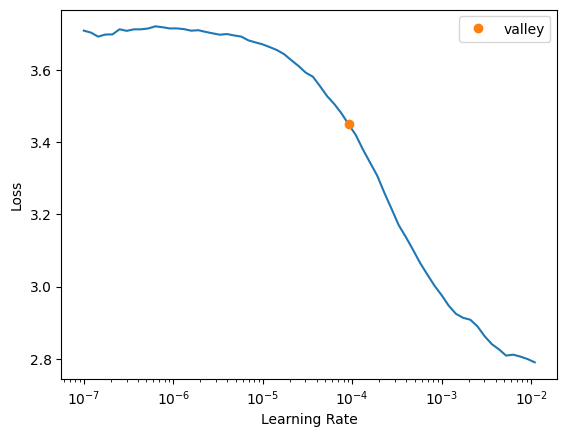
learn.fine_tune(10, 1e-4)
| epoch | train_loss | valid_loss | accuracy_camvid | time |
|---|---|---|---|---|
| 0 | 3.392160 | 2.630378 | 0.255401 | 00:09 |
| epoch | train_loss | valid_loss | accuracy_camvid | time |
|---|---|---|---|---|
| 0 | 2.602331 | 2.325062 | 0.440709 | 00:07 |
| 1 | 2.381318 | 1.799831 | 0.530444 | 00:07 |
| 2 | 2.142349 | 1.332237 | 0.668531 | 00:07 |
| 3 | 1.917440 | 1.123698 | 0.693745 | 00:07 |
| 4 | 1.747154 | 0.993772 | 0.751023 | 00:07 |
| 5 | 1.598631 | 0.996451 | 0.762109 | 00:07 |
| 6 | 1.491493 | 0.948187 | 0.774137 | 00:07 |
| 7 | 1.395746 | 0.869413 | 0.793335 | 00:07 |
| 8 | 1.311806 | 0.876654 | 0.794053 | 00:07 |
| 9 | 1.256938 | 0.868124 | 0.796351 | 00:07 |
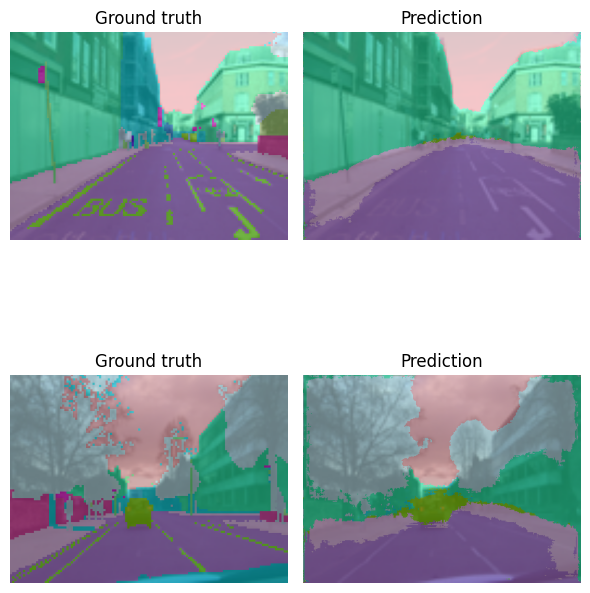
model_type.show_results(model, valid_ds, num_samples=2)
Inference
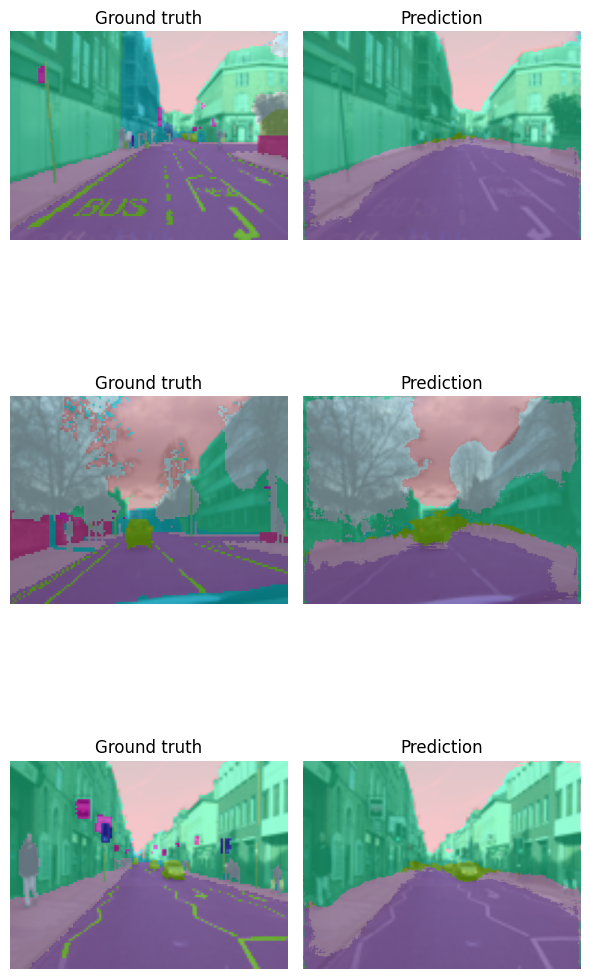
preds = model_type.predict(model, valid_ds)
show_preds(preds=preds[:3])
infer_dl = model_type.infer_dl([valid_ds[0]], batch_size=4, shuffle=False)
preds = model_type.predict_from_dl(model, infer_dl, keep_images=True)
show_sample(preds[0].pred)
0%| | 0/1 [00:00<?, ?it/s]
